Estimating Process Capability in Development & Low-Volume Manufacturing

The process capability index (Ppk) 1 is a widely used summary statistic that describes how well a process produces output within specification limits. For these indices to have predictive meaning, contain adequate estimates of the mean and standard deviation, and provide value in process improvement, the process must have demonstrated adequate statistical control with approximately normally distributed data prior to their calculations. This effort requires a sufficient number of lots (n), usually equal to or greater than 25.
At the same time, it is advantageous to obtain an estimate of process capability early in a product’s life cycle (as soon as a few lots are produced), or an estimate of process capability for those products with infrequent production, as it could otherwise take years to accumulate data for 25 lots.
Within the last decade, quality by design* (QbD) concepts 2 ,3 ,4 ,5 ,6 and practices have permitted greater process understanding in research and design, and have led in turn to increased knowledge and inherent
process capability. This scientific understanding of underlying process and manufacturing conditions enables an assessment of process robustness, even though there may only be a couple of lots produced in development. To differentiate from a formal Ppk capability assessment, a contour-based tool was developed to estimate the percent out of specification (%OOS).
The %OOS contour plot is based on the mean standard deviation and specification of an attribute. Ppk is calculated following manufacture of at least 25 lots of data; several mathematical principles must be demonstrated and the %OOS contours are based on limited direct lot data, along with QbD development experience and fundamental knowledge. Although this experience and knowledge could be substantial, it may not directly translate to a large quantity of lot data during development or in transition to manufacturing.
Additionally, when the contour analysis commences in development, data-driven specifications are often preliminary. The contour tool assesses the fit between experience and the current specification, and helps visualize how well the process meets the specification. In addition, it can be updated as the sample size increases or the specification evolves over time. The contour is a useful visual tool for both small and large number of lots, and for products in development as well as new and marketed products.
A contour plot tool that relates the percent out of specification
(%OOS) to a quality attribute’s average and standard deviation was created to provide an initial or early assessment of process capability based on a limited amount of lot data. This article describes a tool called the process robustness contour plot, its creation, the assumptions, and its application. The article describes how the average %OOS and the upper confidence bound are estimated for a quality attribute of interest, how the tool is used to assess product robustness, and how %OOS relates to process capability. In particular, in a research & development environment where there is limited data, the process robustness contour provides a leading indicator of process and product performance. Details on the computational algorithm are included.
The Value Of Process Robustness Contour Plots
Historically, spreadsheets or similar tabular formats have been used to examine small sets of data. Table A shows an example of such a data set. Examining this spreadsheet may prompt questions such as: How good is the process that produced this data? Do specifications reflect the capability? Can the process be transitioned to manufacturing? What do I expect of the process in the future?
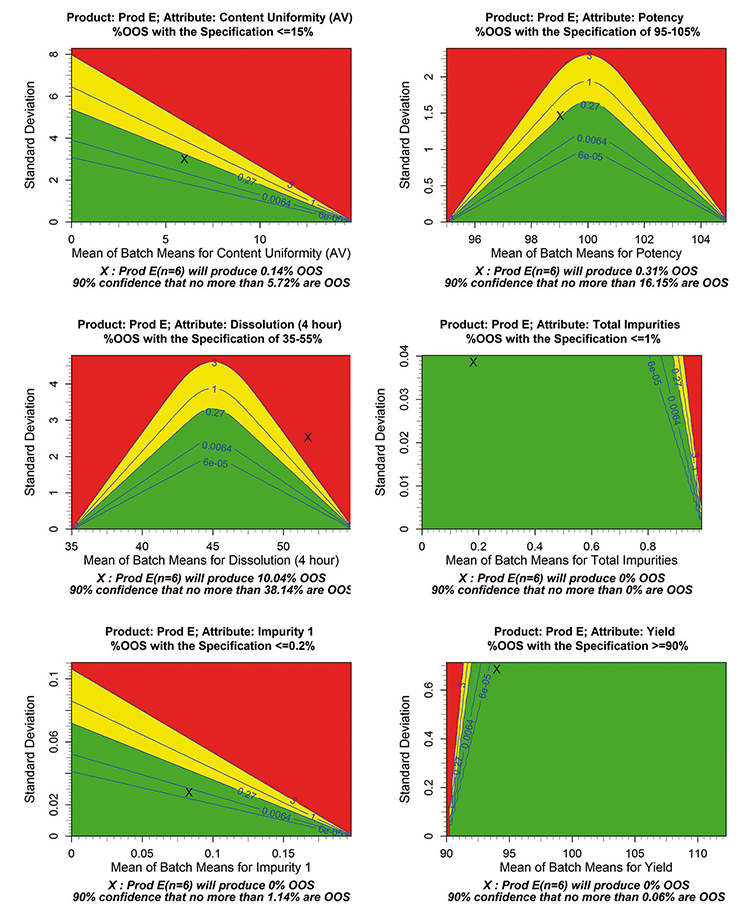
The tabled data indicates that all values are within specifications. Although this is a good start, the process robustness contour plot (Figure 1) visualizes much more information for the six attributes in Table A: content uniformity ICH UDU acceptance value (AV), percent dissolved (at 4 hours), impurity 1, potency, total impurities, and yield (%).
On a process robustness contour plot, the horizontal axis represents the between-lot average and the vertical axis represents the between-lot standard deviation for a quality attribute. An Χ marks the calculated average and standard deviation for each attribute. The calculated average and 90% confidence bound 6 on the predicted %OOS are shown in a plot footnote.
* Quality by design (ICH Q8 [R2]): A systematic approach to development that begins with predefined objectives and emphasizes product and process understanding and process control, based on sound science and quality risk management
| Attribute | Content Uniformity (AV) |
Dissolution (4 hour) |
Impurity 1 | Potency | Total Impurities | Yield |
| Specs | < 15% | 35–55% | <0.2% | 95–105% | < 1% | > 90% |
| Data | 3.24 7.64 9.57 2.73 8.79 3.98 |
52.56 53.96 51.63 47.86 54.60 49.89 |
0.09 0.07 0.12 0.11 0.06 0.05 |
100.95 96.89 99.71 99.85 98.88 97.85 |
0.12 0.16 0.21 0.18 0.19 0.23 |
93.39 93.84 94.91 94.49 93.10 94.28 |
| Attribute | Content Uniformity (AV) |
Dissolution (4 hour) |
Impurity 1 | Potency | Total Impurities | Yield |
| Average | 5.99 | 51.75 | 0.08 | 99.02 | 0.18 | 94.00 |
| Standard Deviation | 3.02 | 2.54 | 0.03 | 1.47 | 0.04 | 0.69 |
The contour plots can be partitioned into regions of estimated %OOS (for given product specifications); they also help compare actual product performance based on estimated product mean and standard deviation across lots. These partitioned contour regions are colored as:
- Green: < 0.27% (good performance)
- Yellow: ≥ 0.27% and < 3% (requires further discussion)
- Red: ≥ 3% (requires attention and further improvement)
The 1% and 3% contours represent estimates in which no more than 1% and 3% of future lots are OOS (on average), respectively. The contour levels of 0.27%, 0.006%, and 6e-5% OOS displayed on the plots are approximately related to Ppk values of 1, 1.33, and 1.67 on average, respectively. Staged goals can be debated; in the case presented here, however, associating the green contour with 0.27% implies a minimum Ppk of about 1 in transition to manufacturing.
Figure 1 shows that for this set of specifications, total impurities, impurity 1, and yield are situated well within the green region; potency and content uniformity approach the yellow region; and dissolution is in the red region. Compared to examining the data spreadsheet, this contour visualization approach offers more and better information for understanding both the data and the process.
Details on the construction, interpretation, and application of the plots will be provided in the next sections.
Contour Plot Construction
During product development, QbD tools and principles can help develop a well-understood process and an implied a level of process robustness that extends beyond the small sample of available data. Process robustness contour plots can be used to assess the resulting robustness via the following steps:
- Identify product quality attributes to be assessed, as well as their units and specifications. The attributes could be identified via a cause-and-effect matrix, the product risk assessment, their criticality, or by other means. For the example, ICH UDU content uniformity acceptance value (AV), % dissolved (4 hours), impurity 1 (%), potency (%), total impurities (%), and yield (%) were identified.
- Collect relevant product data, then calculate the between-lot average and standard deviation. Table B shows calculation for the Figure 1 example. It’s important that the subject matter expert and statistician understand and discuss the data. A discussion around potency, for example, might include:
- As lot release is based on the average potency value, and while multiple tablets might be combined to create a potency value for the lot, only the lot average value is used in the calculation; this summary value represents a sample size of one (lot).
- It may not be possible to check between-lot consistency and lot data normality due to the small sample size. It is suggested, however, to study the data as appropriately as possible by applying statistical tools such as box plots, dot plots, and normal probability plots through data distribution fitting and control charting. Here, prior knowledge about a quality attribute’s distribution may be used to appropriately transform the data to satisfy assumptions.
- Do the data summarized by the product average and standard deviation represent process behavior for the future? Is this the best understanding of combined experimental efforts and theoretical fundamentals? Do the data-driven specifications reflect experience?
- Create a process robustness contour plot for each attribute using the specifications and the summary statistics (average, standard deviation). Each contour plot is based on the specifications provided; once it has been constructed, average and standard deviation for the sample size of n are added to the contour and marked with an Χ. More details on plot construction are provided in the sections that follow.
- Compare the location of the Χ on the contour plot to the predetermined product goal. Based on the location, evaluate the perceived robustness of the product and determine if process-improvement opportunities are appropriate, or if specification revision is an option. The best-case scenario and ultimate manufacturing goal is to be “comfortably” within the green region. If a product lies within the green region but close to the yellow edge, the process may need to shift its mean, reduce variation, or modify its specification. If the product lies within the yellow or red region, more serious discussions around process improvements (e.g., shifting the average, reducing variability) or specification revision are warranted. In these cases, data should be reexamined for completeness, special causes assessed for relevance, measurement system variability addressed, and any fundamental or experimental understanding reassessed. In the Figure 1 example plots, the criteria were differentiated as follows:
- The green region ends at a contour value of 0.27% OOS—a Ppk value of roughly 1. A product with a Ppk of at least 1, presuming this is combined with good process understanding, could typically be transitioned to manufacturing; this would best position manufacturing to make improvements where appropriate and achieve even higher capability levels with experience.
- The yellow region boundary maximum is 3% OOS. With this boundary, there is 90% confidence that for 10 lots the true percent OOS is not worse than 12.6%. The decision as to whether this is acceptable for early manufacturing can be discussed by the team, followed by appropriate actions.
- Beyond the 3% boundary is the red region, where judgment might dictate that the product should not be transitioned to manufacturing without improvement or rationale for modifying the specification.
- Continue to monitor the data, depending upon manufacturing frequency and the number of available lots. When the number of lots is more than 25, the more rigorous standard process control chart methodology should be employed and process capability indices calculated. However, even as the number of lots increases, the %OOS contour plot still provides a nice visual tool to assess process robustness.
- 1Montgomery, Douglas. Introduction to Statistical Quality Control. New York, New York: John Wiley & Sons, Inc., 2004.
- 2International Conference on Harmonisation of Technical Requirements for Registration of Pharmaceuticals for Human Use. ICH Harmonized Tripartite Guideline. “Pharmaceutical Development: Q8 (R2).” Step 4 version, August 2009. http://www.ich.org/fileadmin/Public_Web_Site/ICH_Products/Guidelines/Quality/Q8_R1/Step4/Q8_R2_Guideline.pdf
- 3———. Quality Risk Management: Q9.” Step 4 version, 9 November 2005. http://www.ich.org/fileadmin/Public_Web_Site/ICH_Products/Guidelines/Quality/Q9/Step4/Q9_Guideline.pdf
- 4———. “Pharmaceutical Quality System: Q10.” Step 4 version, 4 June 2008. http://www.ich.org/fileadmin/Public_Web_Site/ICH_Products/Guidelines/Quality/Q10/Step4/Q10_Guideline.pdf
- 5———. “Development and Manufacture of Drug Substances (Chemical Entities and Biotechnological/Biological Entities): Q11.” Step 4 version, 1 May 2012. http://www.ich.org/fileadmin/Public_Web_Site/ICH_Products/Guidelines/Quality/Q11/Q11_Step_4.pdf
- 6Owen, D.B., and Tsushung A. Hua. “Tables of Confidence Limits on the Tail Area of the Normal Distribution.” Communication in Statistics—Simulation and Computation 6, no.3 (1977): 285–311.
Contour Plot Interpretation
Once a process robustness contour plot has been constructed, experts should discuss data validity and distribution (if it is of adequate quantity), measurement system capability, and the current specification, followed by the relative location of the Χ within the colored contour to assess the product performance.
In this assessment, it’s important that the location of the attribute of interest and the ultimate goal for the product be emphasized, not simply if the Χ falls within one specific color zone. Its relative location can indicate, for example, how sensitive the attribute may be to a sample mean change and sample standard deviation; this can indicate potential product performance improvements or a need to modify the data-driven specifications.
As shown in Figure 1, the Χ is in the green region for total impurities, impurity 1, and yield. The Χ is closer to the green/yellow boundary for potency and content uniformity, and is in the red region for dissolution.
Once constructed, the plots should support an active cross-functional group discussion about product performance, which may progress as:
- If the Χ is in the green, the discussion should focus on the representativeness of the data that contributed to the estimated mean and standard deviation, and expectations around the representativeness of the data to the future process.
- For attributes close to the yellow/green boundary, an increase in the standard deviation or shift in product mean will move the Χ toward the yellow zone. A decrease in the standard deviation or a shift in the average would move it to a location confidently within the green.
- For an attribute in the red region (such as dissolution), where the predicted %OOS is 10%, something needs to change. If the specifications are preliminary, there may be some flexibility to modify the specifications in development while still ensuring safety and efficacy. In this case either the specification or the process targeting should change.
If the specifications are correct, the assumptions hold, and the variability estimate appears to be reasonable compared to historic estimates (e.g., other similar products) or variance component analysis (e.g., analytical method development data), the %OOS improvement is achieved through adjusting the mean. In other cases, the standard deviation might need to be reduced, or the underlying process behavior may not produce normally distributed data, so the calculation assumptions should change.
It is important to recognize the uniqueness of data driven-specifications. In some instances, acceptance criteria may be based on fundamental understanding of the impact on safety and efficacy along with quantification of lot data. In this case, for data-driven attributes whose specifications are established during development (e.g., impurities), the process robustness assessment may help evaluate specifications. For final data-driven specifications and those with pharmacopoeial precedent (e.g., potency), the process robustness assessment will help determine how well positioned the product is to meet those specifications in the future. As needed for all attributes, other data sources can be used in the decision-making process. This could include estimates of variability components from methods and process, knowledge from modeling efforts or other relevant data. The team discussion will vary depending on the stage of specification setting and the type of specification.
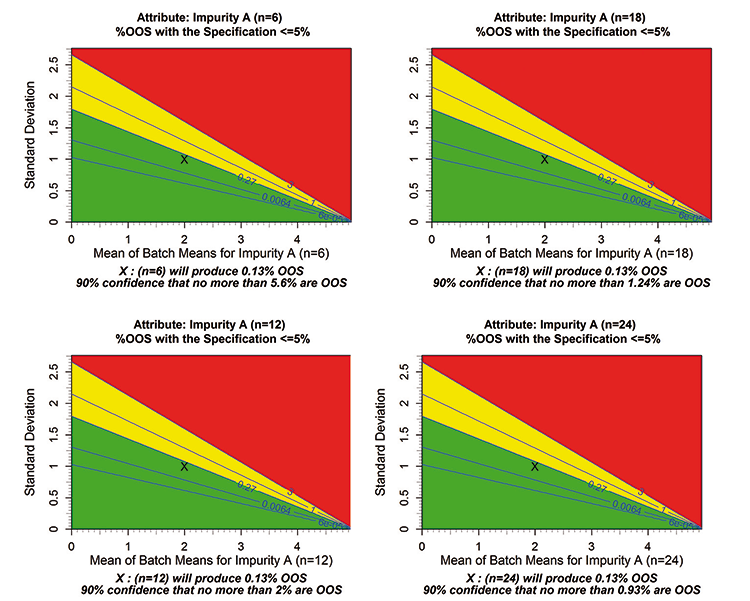
Contour levels of 3%, 1%, 0.27%, 0.006%, and 6e-5% OOS are displayed on the plots. As with any summary statistic, there is variability in the %OOS estimates. This variability is represented in the plot footnote by an upper confidence estimate on the %OOS.
Figure 2 illustrates the effect of the number of lots on the confidence bound. For this example, the average and standard deviations were engineered to remain constant, hence in all cases the average %OOS is estimated as 0.13% even as the number of lots increases. For a sample of six lots, there is 90% confidence that the %OOS will be no more than 5.6%, given the specification and an expectation that the process will operate as it did in development.
As the number of lots increases to 12, 18, and then 24, more direct information on the process expectations is collected, and the upper bound estimates decrease to 2%, 1.24%, and 0.943%, respectively. Note that there is not consideration in the upper bound for any information external to the sample size of 6, 12, 18, or 24 alone. This example illustrates that if the process average and standard deviation remain the same and only the number of lots change, then the average %OOS will not change. Both the %OOS confidence bound along with the average %OOS should therefore be examined.
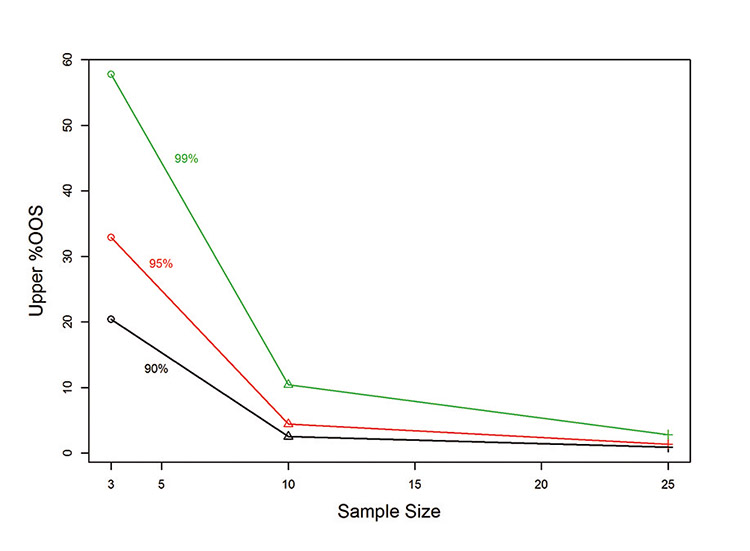
Using the estimated average and standard deviation from Figure 2, Figure 3 illustrates the change in the estimated %OOS confidence bound as the sample size and confidence level vary. The change in the estimated %OOS bound transitions rapidly with an increase in sample size, especially when estimating the 95% and 99% bounds.
Statistically, small numbers of lots provide a particular challenge due to the uncertainty in estimating the process average and process standard deviation, particularly the between-lot process standard deviation. This challenge decreases when the number of lots increases to 10, and essentially is removed at 30 lots, assuming that by then a sufficient amount of process variability has been demonstrated.
Alternatively, external estimates of analytical, material, and process variability can aid decision making for the small number of lots, as mentioned previously. As the tool was developed to include the small numbers of lots (3–10), the 90% confidence bound indicates the most reasonable choice to reflect the larger uncertainty in the variability at these sample sizes, and is used to estimate an upper bound.
Computational Construction
Ranges for the contour plot x and y axes are based on the specification limits and the value of the Χ to be placed on the plot. If only the lower specification limit (LSL) or upper specification limit (USL) is provided, the lower (or upper) range of the x axis is generally set as the LSL (or USL). Ranges for the two-sided specification are based on the LSL and USL provided. If only one x axis endpoint is based on the specification provided, the other x axis endpoint is based on the value of the marked Χ. The lower value of the y axis is generally set at 0, with the upper range based on the y axis value of the marked Χ.
Once the contour ranges are determined, the two-dimensional region is partitioned by dividing each axis into 100 equally spaced intervals (101 × 101 set points), forming 10,000 equal-sized rectangles within the plot region. The OOS% is then computed for each set point (on average), under the assumption that the process is normally distributed with the associated mean and standard deviation at the set point.
Generally speaking, there are three cases associated with the three specification-setting options (LSL only, USL only, two-sided):
- The process has only an LSL [e.g., dissolution (Y) with lower limit or Q value of 80%]. For a set point of (90%, 3%) or 90% average dissolution with a standard deviation 3%, the average %OOS is equal to the probability \( P (Y \leq LSL) = P ( Y \leq 90\% ) = P (Z \leq – 3.33) \approx 0.0004 \), where Z is the standard normal distribution.
- The process has only a USL [e.g., impurity A (Y) with an upper limit of 5%]. For a set point at (2%, 1%), then the average %OOS is equal to the probability \( P (Y \leq LSL \text{ or } Y \geq USL) = P ( Y 95\% \text{ or } Y \geq 105\%) = P (Z \leq –2.5 \text{ or } Z \geq 2.5) \approx 0.0124 \) where Z is again the standard normal distribution.
- The process has both a lower and an upper specification [e.g., assay (Y) with specifications of 95%–105%]. For a set point at (100%, 2%), the average %OOS is equal to the probability \( P (Y \leq LSL \text{ or } Y \geq USL)= P ( Y \leq 95\% \text{ or } Y \geq 105\%) = P (Z \leq –2.5 \text{ or } Z \geq 2.5) \approx 0.0124 \), where Z is again the standard normal distribution.
%OOS Confidence Limit
The preceding section provided examples on the calculation of the %OOS, which then is used to place the Χ on the contour plot. The footnote of the contour plot contains the estimated upper confidence limit on the %OOS. The \( 100 (1 - \alpha)\% \) upper bound on the probability of being OOS is calculated according to the small sample tail area confidence bound algorithm provided in Owen and Hua.4 This section briefly summarizes that calculation.
For a given specification [one-sided lower, i.e., Y ≥ LSL, or upper, i.e., Y ≤ USL or two-sided, i.e., LSL ≤ Y and Y ≤ USL], an upper and a lower confidence bound on the %OOS can be calculated. However, only the two upper confidence bounds are potentially of interest: upper confidence bound for the probability of being less than or equal to LSL [i.e., P (Y ≤ LSL)] and upper confidence bound for the probability of being greater than or equal to USL [i.e., P (Y ≥ USL)]. In the formulas below, it is denoted that n lots of data have been collected with estimated mean (Ӯ) and standard deviation (s) and that \( \Phi \) (•) denotes the standard normal cumulative distribution function.
One-sided lower specification \( Y \geq LSL \) to calculate the upper \( 100(1 – \alpha)\% \) confidence bound for the probability of \( P(Y \leq LSL) \), define \( \eta_L = P(Y \geq LSL) \) and \( K = \frac{ \bar y - LSL}{s} \)
- The lower confidence bound \( \eta_{ \bar L} \) of \( \eta_L \) can be solved numerically from the following equations
- \( P\left(^tn - 1, ncp = \sqrt{n}K_\eta {_ \bar L}^{\leq K\sqrt{n}}\right) = 100 (1 – \alpha)\% \)
- \( \eta_{ \bar L} = \Phi \left ( K_\eta{_ \bar L}\right) \)
- The upper \( 100( 1 – \alpha)\% \) confidence bound for the probability of \( P (Y \leq LSL) \) is \( ( 1 - \eta_{ \bar L} ) \)
One-sided upper specification \( (Y \leq USL) \) to calculate the upper \( 100 (1 – \alpha)\% \) confidence bound for the probability of
\( P (Y \geq USL ) \), define \( \eta_L = P ( Y \geq USL) \) and \( K = – \frac{ \bar y - LSL }{s} \).
- The upper confidence bound \( (n^+_L ) \) of \( \eta_L \) can be solved numerically from the following equations:
- \( P\left(^tn - 1, ncp = \sqrt{n}K_\eta{_L^+}^{\le K\sqrt{\eta}}\right)= 100(1 – \alpha)\% \)
- \( \eta{_L^+} = \Phi \left(K_\eta {_L^+}\right) \)
- The upper \( 100 ( 1 – \alpha)\% \) confidence bound for the probability of \( P (Y \geq USL) \) is \( \left(n{_L^+}\right) \)
Two-sided specification is the sum of \( (\eta_{ \bar L}) \) and \( \left(\eta{_L^+}\right) \) using \alpha / 2 in place of \( \alpha \).
Summary
The %OOS contour plot provides a tool to express product robustness and to provide an insight into process capability for processes with fewer than 25 lots where traditional process capability indices such as Ppk are not meaningful. The plot is superior to examining data in a spreadsheet and can also be applied to greater than 25 lots of data to aid visualization.
To be fully meaningful, the tool assumes product knowledge and confidence in operation beyond the lot data available for calculation. Both average %OOS and the corresponding confidence bound are important to assess product robustness. The relative location of the Χ in the colored zones on the contour plot provides information on product performance and guidance toward process improvement.
Team discussion on the product/process may take the form of whether the process is currently on track/acceptable, if the process needs further attention and investigation, and which improvement actions should be initiated. Additional statistical calculations and modeling could and should be performed to support discussions and decisions.
In all, this tool and the associated process provide a structure to summarize and visually predict process capability.


