The Machine Learning Life Cycle (MLLC): Key Artifacts, Considerations, and Questions

It is an exciting time in life sciences. Many companies have focused initial artificial intelligence/machine learning (AI/ML) adoption efforts on developing and implementing ML trained algorithms, which necessitate following a controlled approach such as the GAMP® 5 ML Sub-System methodology shown below. This blog highlights key artifacts and considerations when implementing AI/ML for GxP use following the GAMP Machine Learning Life Cycle with Sub-System Model
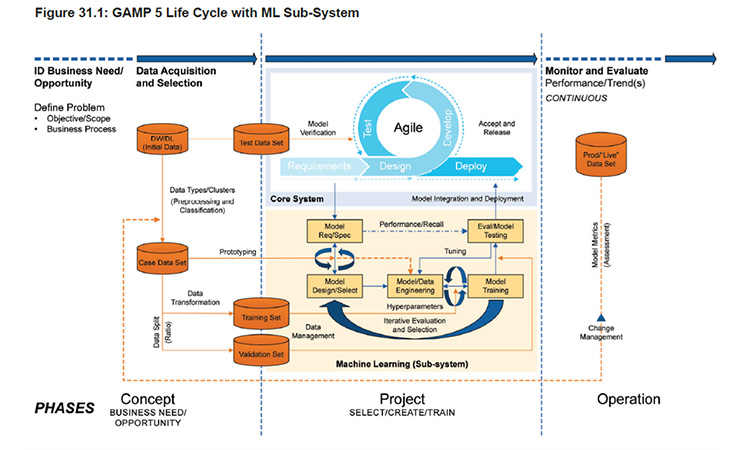
Concept Phase
The concept phase includes understanding the business needs or problem definition, rationale for use of AI, risk-benefit analysis, legal considerations, selection of data sets, review of multiple prototype options, prototype viability testing, identification of human AI team, and third-party support.
Example Artifact: Proof-of-Concept Plan
A proof-of-concept (PoC) plan exploring the elements listed above can be used to determine if an AI-enabled solution is the right choice. Such plans can facilitate quick go/no-go decisions thus allowing non-viable projects to fail fast and ensure that only projects with increased likelihood of success proceed to formal development. Upon approval of the PoC, development, training, tuning, and testing should all be guided by a formal plan.
Key Considerations
| Key Considerations | Questions |
|---|---|
| Cost-Benefit Analysis | What are the benefits? What are the costs? Are the benefits worth the cost, risk, and resource efforts? |
| Legal/Ethics | Is it ethical to use AI for the purpose defined? Are there legal issues with intellectual property? |
| Data Privacy | Will personal health information data be used? If yes, what controls like anonymization and/or encryption need to be put in place? |
| Human AI Teams | Does the AI team have appropriate expertise to develop an AI solution? Does the team have representatives from the business, IT, quality assurance, data science, and legal departments at a minimum? |
| Data Selection | Does the AI team have the right data required to train, test, and validate the model? Does the team have enough data to prepare an independent test data set that is set aside to validate the model at the end? Does the team have enough data to prepare robust training and validation data sets for training and tuning models? Training data not fully representative of the target population will ultimately lead to incorrect model conclusions/outcomes when exposed to real world data. |
| Model Selection | What predefined acceptance criteria is the team going to use to select the optimal model? What is the balance between accuracy and explainability that the team wants to strike? Unexplainable algorithms, also known as black box AI algorithms, which only developers and/or data scientists understand, may lead to failures that cannot be adequately investigated, independently reviewed, etc. |
Project Phase
Once it has been decided that the AI aspects of the solution are viable, the team may proceed to the project phase. The project phase includes an overall plan for development, training, and testing of AI solutions, including considerations such as AI governance, data governance and quality risk management, performance metrics, life cycle documentation requirements and timing, development/training/tuning iterations, model selection, and formal validation of the ML sub-system model.
Artifact: Selected Model
After a prototype has met specific performance criteria, the model testing/formal validation can be performed in alignment with an approved test plan, covering both the traditional software life cycle (SLC) elements and the additional AI elements from the PoC. Upon approval of the development and validation reports, an ongoing monitoring and maintenance plan should be established for the AI solution prior to release of the system for use.
Project phase summary:
- Use what was learned from the evaluation and development of prototypes during the concept phase to build the algorithm, train, iterate, identify model parameters, and tune the algorithm until performance criteria are met.
- Freeze the model and use the unseen test dataset to perform the validation.
- Complete all required documentation and activities according to the plan.
- Deploy the model.
- Implement adaptive AI/ML solutions. In other words, monitor and evaluate the AI/ML solution in routine operation, updating and retraining algorithms as the model performance changes over time, while following proper change management processes.
| Key Considerations | Questions |
|---|---|
| Data Availability | Does the dataset curated for the AI project meet the established criteria such as high quality, number of data points, target population representation, relevance, and labeling? Will the team have enough data once data has been split into train/test/validation datasets? |
| Data-Driven Development Methodology | Shifting from a traditional to a data-driven development methodology places a greater emphasis on data governance, develop/train/tune iterations, transparency, and ethical considerations. Does the organization have a sub-system life cycle management framework to support this type of project? These may include standard operating procedures, tools, templates, skill sets, etc. |
| Bias | Is risk management included early in the AI/ML project life cycle to identify potential biases and require mitigation? |
| Hallucinations | For large language models (LLM), if the model does not know the answer, it can make up information. This is also known as a hallucination. Will the team’s test strategy include risk-based challenges to attempt to force hallucinations? Will the team’s production process include human verification where needed to check for hallucinations? |
| Explainability/ Transparency | Does the ML sub-system process require documentation showing how the algorithm was trained and how the model works? Is architecture clearly defined, and has the rationale for key decisions been documented? Can others on the AI team explain how the model works (at least in general terms) in addition to the developers and data scientists? |
| Transparency | Is there clarity regarding what data was used to train, validate, and test the model? Was it clear why the model was selected? Is transparency supported through adequate formal documentation? |
| Metrics | Have performance metrics been selected at the very start of the project? Are they realistic, justified, relevant, and achievable? The metrics are often updated during the life cycle as the algorithm is built, tested, and tuned. |
| Algorithm Training | Will the training process steps, architecture, data, iterations, data augmentation, data cleansing, failures, retraining, etc., be documented? |
Operation Phase
Once the AI solution has been released for use the operational phase begins.
The operation phase typically includes ongoing performance monitoring, change control (e.g., pre-approved change control plan), and configuration management. Performance monitoring may include periodic re-running of the validation (or gold standard dataset) to confirm the model still meets formally established performance metrics.
| Key Considerations | Questions |
|---|---|
| Ongoing Validation | Once an adaptive model learns from new data and the model is released under change control, performance may drift over time. How will the model be retrained? How will its performance be verified? Will it be subject to regular updates? |
| Model Types (non-adaptive vs. adaptive) | For complex adaptive models what additional controls will be required to be put in place? These may include periodic monitoring against performance criteria (e.g., gold standard dataset), retraining, and increased risk management oversight. |
| Roles and Responsibilities | What additional key stakeholders will need to be involved? These may include the process owner, system owner, and quality assurance teams. It may also include stakeholders from legal, ethics, data science, and regulatory teams. |
| Supporting Processes | What key processes must be followed for the live AI solution? |
Key takeaways:
AI/ML technology offers remarkable capabilities, yet it also introduces specific risks.
- Algorithms trained on limited test/validation data sets may lead models to experience overfitting, resulting in inaccurate results when exposed to real world data. Overfitting arises when the model learning the training data and background noise performs so well that it cannot accurately make predictions on real-world/unseen data.
- Low quality data may lead to inaccurate predictions, the inability of the model to recognize patterns, etc.
- Lack of clear performance metrics and/or mislabeled data may result in the inability to accurately assess models.
- Bias may not be identified and/or appropriately addressed during algorithm development. This can result in discriminatory results.
- Required features may not be included in the training dataset. Important indicators which may include medical history, gene expression, biomarkers, weight, etc., are necessary for accurate results.
Summary and call to action:
AI can automate routine repetitive tasks and accelerate getting new treatments to patients faster. However, to make the most of such technology, the industry must put new controls in place, embracing critical thinking and adaptive processes. These should complement and support existing risk management and SLC processes. A POC plan is needed, along with processes to cover data collection, model development, testing, and ongoing model monitoring and oversight. Processes must also enable responsible AI development, ensuring biases are prevented and that AI is ethical, transparent, and reliable.
Members of the ISPE GAMP Software Automation and AI Special Interest Group are working on operational-level life cycle guidance for the use of compliant AI-enabled computerized systems. In the interim, ISPE GAMP® 5: A Risk-Based Approach to Compliant GxP Computerized Systems (Second Edition) has an excellent appendix (D11) which provides an overview on the topic.
Learn more, attend the upcoming webinar, AI/ML in Regulated (GxP) Life Sciences Sectors - Concept Phase: Business Need & Risk Assessment, on Thursday, 21 March, or explore on-demand webinars covering each phase of the AI/ML life cycle.
Disclaimer:
iSpeak Blog posts provide an opportunity for the dissemination of ideas and opinions on topics impacting the pharmaceutical industry. Ideas and opinions expressed in iSpeak Blog posts are those of the author(s) and publication thereof does not imply endorsement by ISPE.
About the Authors






