Data Science for Pharma 4.0™: Drug Development, & Production—Part 2
This second of a two-part series explores digital transformation and digitalization in the biopharmaceutical industry with information about how data science enables digitalization along the product life cycle. (Part 1 was published in the March-April 2021 issue of Pharmaceutical Engineering.1)
ATMP Manufacturing and Logistics
When a chimeric antigen receptor T cell (CAR-T) therapy needs patient cells as a starting point for drug manufacturing, the process of blood sampling and cell preparation at the hospital has to be documented in a GxP-compliant manner, the integrity of both the transport conditions and the patient’s information needs to be ensured, and all those data finally have to be included in the product’s batch record. This is a real paradigm shift: ATMP manufacturing must not only attend to product safety and quality aspects, but also protect the integrity and confidentiality of patient information. The procedures established for organ transplants across extended distances and relying on a central database and assisted transport may illustrate the complexity of such concepts, but those procedures are far too expensive for application in ATMP therapies. Given the pressures, ATMP production calls for holistic data acquisition along the therapeutic and manufacturing chain; this approach is already partially applied to the compounding of cytostatic drugs.
Some gene therapeutic concepts have even deeper connections to data science. The possibility of producing an RNA vaccine based on the gene expression profile of a patient’s tumor directly links patient information to drug manufacturing. In the manufacture and distribution of this type of product, the patient’s identity and clinical data that may be of interest to third parties must be protected. An integrated data safety model consisting of different layers of protection for data safety and integrity for all aspects should be implemented. Starting with a system that is validated according to GAMP® 57 for all critical parts of the diagnostic and manufacturing chain, data integrity must be ensured by the system operations that control the validated state. A third layer of data integrity should be set up for the complete IT management system involved, including, for example, hosted services. Finally, a concept should be in place to ensure cybersecurity throughout the data chain. For these reasons, digitalization and data integrity shall be seen as requirements for data science.
Another consideration is that the drug manufacturer could possibly use a scientific data model to intervene directly in the therapeutic strategy chosen for a patient. Data science may thus not only enable progress in drug manufacturing, but also enhance therapeutic success. Detailed therapeutic data may further return from the patient’s hospital to the drug license owner and improve the data model, with implications for both the therapeutic strategy and the manufacturing process.
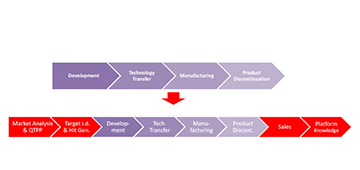
Holistic Data Science Concept
Industry 4.0 involves the integration of many individual tools. Some data science tools already exist and are in use. However, the individual data science tools have no Pharma 4.0™ relevance unless they are integrated into a holistic data science concept.
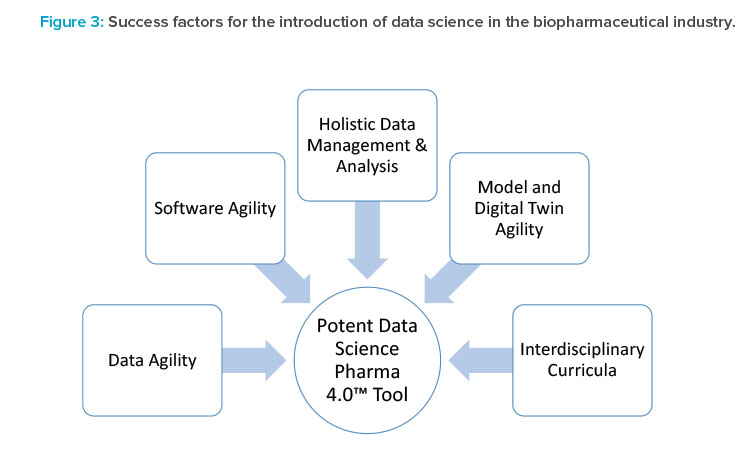
- Several levels of integration are needed to turn individual data science tools into a powerful Pharma 4.0™ environment (Figure 3). Integration of such tools needs to be flexible by design because the outcome should be a flexible manufacturing platform for multiple products and include a product life-cycle approach. The following are key priorities:
- Software agility: We propose DevOps techniques and a DevOps mindset, as an agile approach, without gigantic deployment, test, or validation overheads. Although DevOps applications are currently successful, especially for software-as-a-service (SaaS) deployment, DevOps is not yet fully established for IT/operational technology (OT) environments in pharmaceutical companies (see Part 1 of this series).
- Data agility: SaaS cloud solutions will be the future basis for data and knowledge exchange, although cybersecurity concerns must first be solved technically and at the political level. Moreover, we are convinced that SaaS tools will provide the agility required for exchanging data as well as model and digital twin life-cycle management.
- Holistic data management and data analysis: Plug-and-produce solutions, as exemplified in the Pharma 4.0™ Special Interest Group (SIG) initiatives, include standardized data interfaces and consistent data models. Data availability, however, is not sufficient. We also need the ability to holistically analyze different data sources and integrate time-value data sets, spectra, images, ELNs, LIMSs, and manufacturing execution system data—these are being targeted in the Pharma 4.0™ SIG Process (Data) Maps, Critical Thinking workgroup.
- Model and digital twin agility: To ensure that data models and digital twins can be adapted along the life cycle and continuously deployed in a GxP environment, the industry needs a flexible, but still validatable, environment for capturing and deploying knowledge. This environment may include artificial intelligence and machine learning, as well as hybrid solutions developed for all kinds of scenarios. Therefore, we need validated workflows for automated model development and digital twin deployment, including integrated model maintenance, model management, and fault detection algorithms.8,9 This should be an extension of the GAMP® 5 guidance.7
- Interdisciplinary teams: Numerous data scientists will be required to run the facilities of the future. Standardization of workforce development should help ensure that expectations for training and proficiency are uniform across the industry. Agreement on standard curricula and assessment measures would facilitate this. Initiatives should be launched at universities and governmental organizations but should also involve industry training centers.
Conclusion
Digitalization in the bioprocessing industry is advanced by focusing on knowledge and integrating the complete spectrum of data science applications into the product life cycle. The industry needs life-cycle solutions, such as feedback loops in CPV, for knowledge management. The data science framework for these solutions is already set, but we need to set up business process workflows according to ICH Q10 guidance, automate PCS workflows, and agree on core plots for trending of regular manufacturing and CPV solutions. We have to “live” ICH Q12, facilitated by data science tools.
The main obstacle to achieving this goal is convincing all industry stakeholders—individuals, teams, groups, departments, business units, management, leadership, and C-level executives—of the benefits of making value out of data. Google and Facebook may serve here as well-known examples of companies that have translated data into value.
The industry urgently needs to invest in interdisciplinary curricula as a midterm strategy. And those of us who are data science–trained engineers are obligated to show the benefits of integrated tools and workflows and explain what the industry essentially needs throughout the product life cycle.
Data Science for Pharma 4.0™, Drug Development, & Production—Part 1
Digital transformation and digitalization are on the agenda for all organizations in the biopharmaceutical industry.








